
TL;DR
- Un LLM, c'est un reseau de neurones qui predit le prochain token. C'est tout. Mais de cette simplicite emerge des capacites absurdes.
- L'architecture Transformer (2017) a tout change grace a un mecanisme : l'attention.
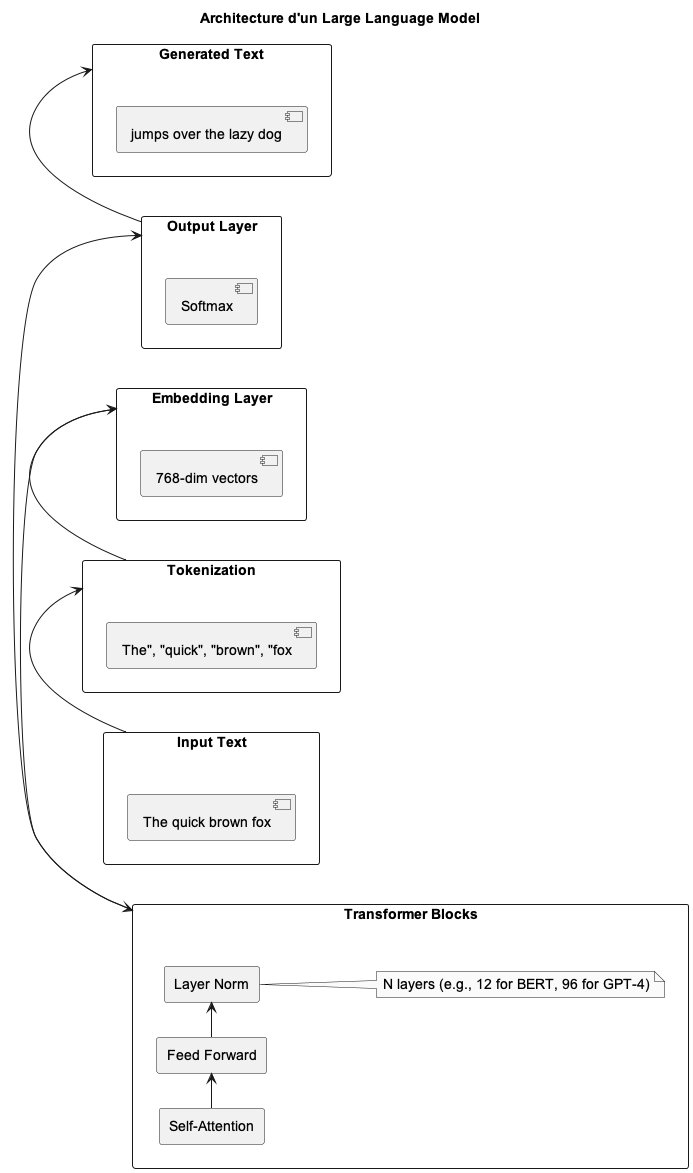
- Le texte passe par tokenization, embedding, puis des couches d'attention avant de generer un output.
- Temperature, top-k, top-p : des parametres qui controlent la creativite vs la fiabilite.
- Comprendre ca change ta facon de prompter, de debugger, et de designer des systemes avec des LLM.
Tu utilises un LLM tous les jours. Mais sais-tu ce qui se passe dedans ?
Tu envoies un prompt a ChatGPT ou Claude. Tu recois une reponse. Ca marche. Mais quand ca ne marche pas -- quand le modele hallucine, repete en boucle, ou rate completement le contexte -- tu es aveugle. Tu ne sais pas pourquoi.
Comprendre le fonctionnement d'un LLM, c'est pas juste de la culture generale. Ca change ta facon de prompter, de debugger, et de construire avec. Un dev qui sait comment le moteur tourne fait de meilleurs choix qu'un dev qui appuie sur l'accelerateur en esperant que ca passe.
Cet article est le deuxieme de la serie "Comprendre l'IA en 2026". On pose les bases techniques. Pas un cours magistral -- juste ce qu'un dev a besoin de savoir pour travailler avec ces modeles sans etre dans le brouillard.
C'est quoi un LLM, concretement ?
Un LLM, c'est un reseau de neurones entraine pour faire une seule chose : predire le prochain token. C'est tout. Pas de comprehension, pas de raisonnement au sens humain. Juste de la prediction statistique sur des sequences de texte.
Mais de cette simplicite emerge des capacites qui semblent magiques. Traduire, resumer, coder, raisonner -- tout ca decoule de la meme operation fondamentale, repetee des milliards de fois sur des quantites massives de texte.
L'histoire en bref :
- Avant 2017 : les RNN et LSTM traitent le texte de facon sequentielle, mot par mot. Ca marche, mais c'est lent et ca oublie le debut de la phrase quand elle est longue.
- 2017 : Google publie "Attention Is All You Need". L'architecture Transformer arrive. Tout change.
- 2018-2020 : BERT, GPT-2, GPT-3. Les modeles grossissent, les capacites explosent.
- 2022+ : ChatGPT, Claude, Llama. Les LLM deviennent des outils grand public.
Le Transformer, c'est le moment ou tout a bascule. Voyons pourquoi.
Le Transformer : l'architecture qui a tout change
Avant le Transformer, les modeles de langage traitaient le texte sequentiellement. Un mot apres l'autre, dans l'ordre. Les RNN ne pouvaient pas paralleliser -- chaque etape dependait de la precedente. Resultat : c'etait lent a entrainer, et le modele avait du mal a maintenir le contexte sur de longues sequences.
Le Transformer resout ces deux problemes d'un coup. Il traite tous les tokens en parallele, et il utilise un mecanisme d'attention pour que chaque token puisse "regarder" tous les autres tokens de la sequence. Plus besoin de passer l'information de proche en proche.
Trois innovations cles :
- Le mecanisme d'attention : chaque token peut se connecter directement a n'importe quel autre token de la sequence. C'est le coeur du systeme.
- L'encodage positionnel : comme le modele voit tous les tokens en meme temps, il a besoin d'un signal pour savoir dans quel ordre ils apparaissent. On ajoute des vecteurs de position aux embeddings.
- Les couches feed-forward : apres l'attention, chaque token passe dans un reseau de neurones classique qui transforme sa representation.
Le pipeline complet d'un LLM :
Texte → Tokenization → Embedding + Position → [Attention → Feed-Forward] x N → Output
Chaque etape merite qu'on s'y arrete.
Tokenization : comment le texte devient des nombres
Un LLM ne voit pas du texte. Il voit des nombres. La tokenization est l'etape qui transforme une chaine de caracteres en une sequence d'identifiants numeriques.
La methode la plus courante s'appelle BPE (Byte Pair Encoding). L'idee : commencer avec des caracteres individuels, puis fusionner les paires les plus frequentes en sous-mots. "bonjour" pourrait etre un seul token, mais "anticonstitutionnel" sera decoupe en plusieurs morceaux.
# Exemple simplifie de tokenization (GPT-4 style)
text = "Bonjour le monde"
tokens = ["Bon", "jour", " le", " monde"]
token_ids = [23546, 15830, 514, 28362]
# 4 tokens pour 3 mots
Pourquoi c'est important pour toi en tant que dev :
- Le cout : tu payes par token, pas par mot. Un texte en francais genere plus de tokens qu'en anglais.
- La fenetre de contexte : un modele avec un context window de 128K tokens, c'est une limite sur les tokens, pas sur les mots. Un livre de 300 pages tient. Deux livres, non.
- Le comportement : les tokens rares ou mal decoupes peuvent produire des resultats bizarres. C'est pour ca que les LLM sont parfois mauvais en orthographe ou en comptage de lettres.
Embeddings : capturer le sens dans des vecteurs
Une fois tokenise, chaque token est converti en un vecteur dense via un embedding. Un vecteur de 768 a 12 288 dimensions selon le modele, ou chaque dimension encode un aspect du sens.
# Conceptuellement
embedding("roi") = [0.21, -0.45, 0.89, ...] # 768 dimensions
embedding("reine") = [0.19, -0.42, 0.91, ...] # tres proche de "roi"
embedding("table") = [-0.67, 0.33, -0.12, ...] # tres eloigne
L'idee puissante : les mots qui ont un sens similaire finissent proches dans l'espace vectoriel. Et les relations sont preservees : roi - homme + femme ≈ reine. Ce n'est pas de la magie -- c'est le resultat d'un entrainement sur des milliards de phrases ou ces mots apparaissent dans des contextes similaires.
Ces embeddings sont la matiere premiere de tout le reste. C'est a partir de ces vecteurs que le mecanisme d'attention va travailler.
Le mecanisme d'attention : le coeur du systeme
C'est ici que la magie opère. Le mecanisme d'attention permet a chaque token de "consulter" tous les autres tokens de la sequence pour decider quoi faire.
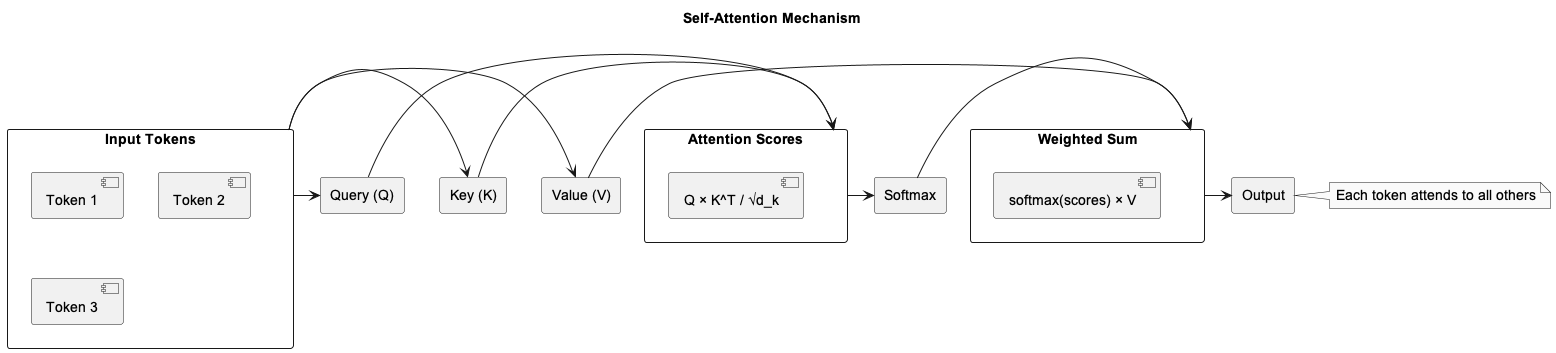
L'intuition : imagine que tu lis la phrase "Le chat est monte sur le toit parce qu'il etait agile". Pour comprendre "il", tu dois relier ce token a "chat", pas a "toit". C'est exactement ce que fait l'attention.
Comment ca marche, concretement ? Chaque token est projete en trois vecteurs :
- Query (Q) : "qu'est-ce que je cherche ?"
- Key (K) : "qu'est-ce que j'offre comme information ?"
- Value (V) : "quel contenu je fournis si on me selectionne ?"
Input → [Query Q] ──┐
Input → [Key K] ──┤── Score = Q x K^T / sqrt(d_k) → Softmax → Weights x V → Output
Input → [Value V] ──┘
En pseudo-code :
def scaled_dot_product_attention(Q, K, V):
scores = Q @ K.T / sqrt(d_k) # similarite entre queries et keys
weights = softmax(scores) # normalisation en probabilites
output = weights @ V # combinaison ponderee des values
return output
La division par sqrt(d_k) empeche les scores de devenir trop grands, ce qui rendrait le softmax trop "pointu" (un seul token monopoliserait toute l'attention).
Multi-Head Attention : plusieurs perspectives en parallele

Un seul mecanisme d'attention capture un seul type de relation. Mais dans une phrase, il y a plusieurs types de relations simultanees : syntaxiques, semantiques, co-references...
La solution : executer plusieurs mecanismes d'attention en parallele (les "tetes"). GPT-3 en utilise 96. Chaque tete apprend a se specialiser sur un type de relation different.
Input ──→ [Tete 1: syntaxe] ──┐
──→ [Tete 2: semantique] ──┤── Concatener → Projection lineaire → Output
──→ [Tete 3: coref] ──┘
──→ ...
C'est comme regarder un texte sous plusieurs angles simultanement. Une tete peut suivre les relations sujet-verbe. Une autre suit les pronoms et leurs antecedents. Une troisieme relie les synonymes. Ensemble, elles construisent une representation riche du contexte.
Comment un LLM apprend
L'entrainement d'un LLM se fait en trois etapes, chacune avec un objectif different.
Pre-training
C'est la phase la plus couteuse. Le modele ingere des teraoctets de texte (internet, livres, code, Wikipedia...) et apprend a predire le prochain token. Un pre-training de GPT-4 a coute des dizaines de millions de dollars en compute.
# L'objectif est simple
input = "Le chat est monte sur le"
target = "toit"
# Repeter des billions de fois sur tout internet
A la fin de cette phase, le modele "sait" beaucoup de choses, mais il est inutilisable en pratique. Il complete du texte, point. Tu lui poses une question, il genere... la suite probable d'un article Wikipedia.
Fine-tuning
On affine le modele sur des donnees specifiques : des paires question/reponse, des conversations, du code commente. Le fine-tuning specialise le modele pour un usage concret.
RLHF
Le RLHF (Reinforcement Learning from Human Feedback) est ce qui transforme un modele de completion de texte en assistant utile. Des humains evaluent les reponses du modele, et on entraine un modele de recompense pour guider le LLM vers des reponses utiles, honnetes et inoffensives.
C'est le RLHF qui a transforme GPT-3 (impressionnant mais inutilisable) en ChatGPT (utile au quotidien). Le modele sous-jacent n'a pas fondamentalement change. C'est l'alignement avec les attentes humaines qui a tout change.
Comment un LLM genere du texte
A l'inference, la generation fonctionne token par token, de gauche a droite. Le modele recoit tous les tokens precedents, calcule une distribution de probabilite sur le vocabulaire entier, et choisit le prochain token.
Trois parametres controlent ce choix :
Temperature : controle le "niveau de creativite". A 0, le modele choisit toujours le token le plus probable (deterministe). A 1, il explore davantage. Au-dela de 1, c'est le chaos.
# temperature basse = previsible, factuel
# temperature haute = creatif, risque
scaled_logits = logits / temperature
probabilities = softmax(scaled_logits)
Top-k : ne considere que les k tokens les plus probables. Avec top-k=50, les 49 950 autres tokens du vocabulaire sont ignores, meme s'ils avaient une probabilite non nulle.
Top-p (nucleus sampling) : ne considere que les tokens dont la probabilite cumulee atteint p. Avec top-p=0.9, on prend les tokens les plus probables qui representent ensemble 90% de la masse de probabilite.
En pratique :
- Temperature 0 + top-k 1 : reponse deterministe. Ideal pour du code, des faits.
- Temperature 0.7 + top-p 0.9 : bon equilibre pour de la redaction.
- Temperature 1.0+ : brainstorming, creation. Mais attention aux hallucinations.
Les limites a connaitre
Un LLM n'est pas un oracle. Comprendre ses limites, c'est aussi important que comprendre son fonctionnement.
Les hallucinations : un LLM ne "sait" rien. Il predit des tokens. Quand il n'a pas assez de signal statistique, il genere du texte plausible mais faux. C'est pas un bug, c'est un comportement inherent a la prediction de tokens. Tu ne peux pas l'eliminer, seulement le reduire (avec du RAG, des guardrails, de la verification).
La fenetre de contexte : meme avec 128K ou 1M de tokens, il y a une limite. Et l'attention se dilue sur les longs contextes -- le modele est meilleur au debut et a la fin qu'au milieu (le "lost in the middle" problem).
Le cout : chaque token d'input et d'output a un prix. Un pipeline mal concu peut couter cher. Compter ses tokens, c'est aussi important que compter ses requetes SQL.
Les biais : le modele reproduit les biais presents dans ses donnees d'entrainement. Si internet dit que les developpeurs sont des hommes, le modele aura ce biais. C'est un probleme connu, partiellement mitige par le RLHF, mais jamais completement resolu.
Pourquoi comprendre ca change tout
En tant que dev, savoir comment un LLM fonctionne, ca te donne des super-pouvoirs concrets :
- Meilleurs prompts : tu sais que le modele predit des tokens, donc tu structures ton prompt pour guider cette prediction. Tu donnes des exemples (few-shot), tu cadres le format de sortie, tu evites l'ambiguite.
- Meilleur debugging : quand le modele hallucine, tu comprends pourquoi. Quand il repete en boucle, tu sais que c'est un probleme de sampling. Quand il rate le contexte, tu sais que c'est un probleme de fenetre.
- Meilleur design de systemes : tu sais quand utiliser du RAG plutot que du fine-tuning. Tu sais que le prompt engineering couvre 80% des cas. Tu dimensionnes tes chunks pour la tokenization, pas au pif.
- Meilleure intuition : tu sens les limites avant de les cogner. Tu ne demandes pas a un LLM de compter des lettres ou de faire de l'arithmetique precise. Tu le laisses faire ce qu'il fait bien : raisonner sur du langage.
C'est la difference entre un dev qui utilise un outil et un dev qui comprend son outil.
Ressources
- Attention Is All You Need -- le paper original qui a lance le Transformer
- Andrej Karpathy - Let's build GPT -- construire un GPT from scratch, de zero
- 3Blue1Brown - Neural Networks -- visualiser les reseaux de neurones
- Hugging Face Transformers -- experimenter avec les modeles
- Stanford CS224N -- cours complet NLP
La suite
Cet article fait partie de la serie "Comprendre l'IA en 2026".
- Ce qui s'est passe en IA depuis ChatGPT -- la frise chronologique 2022-2026.
- Cet article : Comment fonctionnent les LLM -- l'architecture Transformer, l'attention, la tokenisation.
- RAG, MCP, function calling -- le kit du dev en 2026 -- les patterns d'integration concrets.
- Les agents IA ne sont pas du hype -- quand le LLM planifie, raisonne et agit en autonomie.
- Rattraper 3 ans d'IA en 8 semaines -- le parcours concret pour les devs.


